Что такое значение EOF и '\ 0' в C. C что такое
c++ - Что такое значение EOF и '\ 0' в C
NULL и '\0' гарантированно оцениваются до 0, поэтому (с соответствующими приведениями) их можно считать одинаковыми по стоимости; однако они представляют две разные вещи: NULL - это нулевой (всегда недействительный) указатель, а '\0' - это ограничитель строки. EOF вместо этого является отрицательной целочисленной константой, которая указывает конец потока; часто это -1, но стандарт ничего не говорит о его фактическом значении.
C и С++ отличаются типом NULL и '\0':
- в С++ '\0' есть char, а в C это an int; это потому, что в C все символьные литералы считаются int s.
-
в С++ NULL является "просто" интегралом 0, а в C его можно определить как 0, отлитый от void *; это не может быть сделано в С++ (и это явно запрещено в заметке), поскольку, будучи более строгим в С++ преобразованиями указателей, void * неявно не конвертируется в любой другой тип указателя, поэтому, если NULL был void *, необходимо было бы привязать его к типу целевого указателя при назначении:
Соответствующие стандартные цитаты:
NULL
NULL - целочисленный тип, гарантированный для вычисления 0:
4.10 Преобразования указателей
Константа нулевого указателя является интегральным постоянным выражением (5.19) rvalue целочисленного типа, который вычисляется до нуля. Константа нулевого указателя может быть преобразована в тип указателя; результатом является нулевое значение указателя этого типа и отличается от любого другого значения указателя на объект или указателя на тип функции. Два значения нулевого указателя того же типа сравниваются равными. Преобразование константы нулевого указателя в указатель to cv-qualified type - это одно преобразование, а не последовательность преобразования указателя с последующим квалификационным преобразованием (4.4).
18.1 Типы
[...] Макрос NULL представляет собой константу нулевого указателя С++, определенную реализацией, в этом международном стандарте (4.10). (Возможные определения включают 0 и 0L, но не (void*)0).
'\0'
Должно существовать 0-значение char:
Основной набор символов выполнения и набор символов широкого исполнения должны содержать [...] нулевой символ (соответственно нулевой широкий символ), представление которого имеет все нулевые биты.
'\0' является литералом char:
2.13.2 Литералы символов
Символьный литерал - это один или несколько символов, заключенных в одинарные кавычки, как в 'x', необязательно предшествующие букве L, как в Lx. Литеральный символ, который не начинается с L, является литералом обычного характера, также называемым литералом узкого символа. Литерал обычного характера, который содержит один c- char, имеет тип char со значением, равным числовому значению кодирования c- char в наборе символов выполнения.
и это значение равно 0, поскольку эта escape-последовательность определяет его значение:
Выход \ooo состоит из обратного слэша, за которым следуют одна, две или три восьмеричные цифры, которые берутся для указания значения желаемого символа.
'\0' используется для прекращения литералов строк:
2.13.4 Строковые литералы
После любой необходимой конкатенации, в фазе перевода 7 (2.1), '\0' добавляется к каждому строковому литералу, так что программы, которые сканируют строку, могут найти ее конец.
EOF
Определение EOF делегировано стандарту C89 (как указано в § 27.8.2 "Файлы библиотеки C" ), где оно определяется как отрицательное целое, специфичное для реализации.
NULL
Нулевой указатель представляет собой целое число 0, необязательно отлитое от void *; NULL - нулевой указатель.
6.3.2.3 Указатели
[...] Целочисленное константное выражение со значением 0 или такое выражение, отлитое для типа void *, называется константой нулевого указателя. (Макрос NULL определяется в <stddef.h> (и других заголовках) как константа нулевого указателя, см. 7.17.) Если константа нулевого указателя преобразуется в тип указателя, результирующий указатель, называемый нулевым указателем, гарантируется для сравнения неравнозначно с указателем на любой объект или функцию.
7.17 Общие определения <stddef.h>
[...] Макросы
NULL
который расширяется до константы нулевого указателя, определяемой реализацией; [...]
'\0'
'\0' - целое число со значением 0 и используется для прерывания строк:
5.2.1 Наборы символов
6.4.4.4 Символьные константы
Целочисленная символьная константа представляет собой последовательность одного или нескольких многобайтовых символов, заключенных в одиночных кавычках, как в 'x'. [...]
Октальные цифры, которые следуют за обратной косой чертой в восьмеричной escape-последовательности, считаются частью построения одного символа для целочисленной символьной константы или одного широкого символа для широкой символьной константы. Численное значение сформированного восьмеричного целого задает значение желаемого символа или широкого символа. [...]
Целочисленная символьная константа имеет тип int.
EOF
EOF - это отрицательное целое число
7.19 Вход/выход <stdio.h>
7.19.1 Введение
EOF
который расширяется до целочисленного постоянного выражения, с типом int и отрицательным значением, которое возвращается несколькими функциями для указания конца файла, то есть больше нет ввода из Поток
Основы c#. Урок 1. Что такое c#?
C# (произносится Си-Шарп) - это новый язык программирования от компании Microsoft. Он входит в новую версию Visual Studio - Visual Studio.NET. Кроме C# в Visual Studio.NET входят Visual Basic.NET и Visual C++. Кроме того фирма Borland объявила, что последующие версии C++ Builder и Delphi будут поддерживать платформу .NET (последнее лежит в русле политики Borland - так, например, нынешние версии C++ Builder и Delphi поддерживают, например, такую технологию от Microsoft, как ActiveX).
Одна из причин разработки нового языка компанией Microsoft - это создание компонентно-ориентированного языка для новой платформы .NET. Другие языки были созданы до появления платформы .NET, язык же C# создавался специально под эту платформу и не несет с собой груза совместимости с предыдущими версиями языков. Хотя это не означает, что для новой плятформы это единственный язык.
Еще одна из причин разработки компанией Microsoft нового языка программирования - это создание альтернативы языку Java. Как известно, реализация Java у Microsoft не была лицензионно чистой - Microsoft в присущей ей манере внесла в свою реализацию много чего от себя. Компания Sun, владелица Java, подала на Microsoft в суд, и Microsoft этот суд проиграла. Тогда Microsoft решила вообще отказаться от Java, и создать свой Java-подобный язык, который и получил название C#. Что будет с Java после выхода C# - пока неизвестно. Скорей всего эти языки будут существовать оба, хотя ясно, что одна из целей разработки C# - это противоборство именно с Java (недаром C# называют еще Java-killer'ом).
Основы c#. Урок 2. Что такое net Runtime?
Если перевести слова NET Runtime на русский язык, то мы получим что-то вроде "Среда выполнения". Именно вы этой среде и выполняется код, получаемый в результате компиляции программы написанной на C#. NET Runtime основын не на ассемблере (т. е. не на коде, родном для процессора), а на некотором промежуточном коде. Отдаленно он напоминает виртуальную Java машину. Только если в случае Java у нас был только один язык для виртуальной машины, то для NET Runtime таких языков может быть несколько. Теоретически программа для среды NET Runtime может выполняться под любой операционной системой, в которой NET Runtime установлена. Но на практике пока единственная платформа для этого - это Windows.
NET Runtime состоит из нескольких частей. Одна из них - это Common Language Runtime. Это, говоря кратко, это некоторый набор стандартов, котрые должны поддерживать все языки платформы .NET. Например, в предыдущих версиях Visual Studio была такая проблема, что разные языки по разному хранили данные одного по идее типа. Так, скажем, тип целого в Visual Basic'е занимал два байта, а в Visual C++ - четыре. А это порождало кучу проблем при совместном использовании языков. Так вот, Common Language Runtime как раз в частности и определяет стандартные для все языков .NET типы данных. И уже есть гарантии, что целый тип в одном языке будет в точности соответствовать одноименному типу в другом.
Еще одна важная часть NET Runtime - это набор базовых классов. Их очень много (порядка несколько тысяч). Кроме того, эти классы относятся не к конкретному языку, а к NET Runtime. Т. е. мы получаем набор классов, общий для всех языков .NET, что достаточно удобно.
Далее. Именно NET Runtime берет на себя некоторые рутинные функции. Например в нем организована сборка мусора. И если раньше программисту приходилось самому освобождать объекты, созданные динамически, то теперь эту задачу берет на себя среда NET Runtime. Еще одно свойство среды NET Runtime - это проверка типов. Означает это вот что. Когда программа выполняется, то в принципе некоторой функции можно подсунуть параметр неправильного типа. Скажем вместо целого подставить действительное число или еще что-нибудь в этом роде. Языки типа C++ свои параметры функций не проверяют, в результате чего записанная переменная большего размера может повредить чужую область памяти и программа может просто рухнуть. Еще классический пример на эту тему - это выход за пределы массива. В NET Runtime же такого невозможно. NET Runtime сама позаботится о проверке типов и других вещах.
Существует несколько языков для NET Runtime. В настоящее время это C#, VB.NET и Visual C++. Кроме того фирма Borland объявила, что ее продукты C++ Builder и Delphi тоже будут поддерживать NET Runtime.
studfiles.net
C++ | Что такое указатели
Что такое указатели
Последнее обновление: 22.09.2017
Указатели представляют собой объекты, значением которых служат адреса других объектов (переменных, констант, указателей) или функций. Как и ссылки, указатели применяются для косвенного доступа к объекту. Однако в отличие от ссылок указатели обладают большими возможностями.
Для определения указателя надо указать тип объекта, на который указывает указатель, и символ звездочки *. Например, определим указатель на объект типа int:
int *p;Пока указатель не ссылается ни на какой объект. При этом в отличие от ссылки указатель необязательно инициализировать каким-либо значением. Теперь присвоим указателю адрес переменной:
int x = 10; // определяем переменную int *p; // определяем указатель p = &x; // указатель получает адрес переменнойДля получения адреса переменной применяется операция &. Что важно, переменная x имеет тип int, и указатель, который указывает на ее адрес, тоже имеет тип int. То есть должно быть соответствие по типу.
Если мы попробуем вывести адрес переменной на консоль, то увидим, что он представляет шестнадцатиричное значение:
#include <iostream> int main() { int x = 10; // определяем переменную int *p; // определяем указатель p = &x; // указатель получает адрес переменной std::cout << "p = " << p << std::endl; return 0; }В каждом отдельном случае адрес может отличаться, но к примеру, в моем случае машинный адрес переменной x - 0x60fe98. То есть в памяти компьютера есть адрес 0x60fe98, по которому располагается переменная x. Так как переменная x представляет тип int, то на большинстве архитектур она будет занимать следующие 4 байта (на конкретных архитектурах размер памяти для типа int может отличаться). Таким образом, переменная типа int последовательно займет ячейки памяти с адресами 0x60FE98, 0x60FE99, 0x60FE9A, 0x60FE9B.
И указатель p будет ссылаться на адрес, по которому располагается переменная x, то есть на адрес 0x60FE98.
Но так как указатель хранит адрес, то мы можем по этому адресу получить хранящееся там значение, то есть значение переменной x. Для этого применяется операция * или операция разыменования, то есть та операция, которая применяется при определении указателя. Результатом этой операции всегда является объект, на который указывает указатель. Применим данную операцию и получим значение переменной x:
Консольный вывод:
Address = 0x60fe98 Value = 10Значение, которое получено в результате операции разыменования, можно присвоить другой переменной:
int x = 10; int *p = &x; int y = *p; std::cout << "Value = " << y << std::endl; // 10И также используя указатель, мы можем менять значение по адресу, который хранится в указателе:
int x = 10; int *p = &x; *p = 45; std::cout << "x = " << x << std::endl; // 45Так как по адресу, на который указывает указатель, располагается переменная x, то соответственно ее значение изменится.
Создадим еще несколько указателей:
#include <iostream> int main() { short c = 12; int d = 10; short s = 2; short *pc = &c; // получаем адрес переменной с типа short int *pd = &d; // получаем адрес переменной d типа int short *ps = &s; // получаем адрес переменной s типа short std::cout << "Variable c: address=" << pc << "\t value=" << *pc << std::endl; std::cout << "Variable d: address=" << pd << "\t value=" << *pd << std::endl; std::cout << "Variable s: address=" << ps << "\t value=" << *ps << std::endl; return 0; }По адресам можно увидеть, что переменные часто расположены в памяти рядом, но не обязательно в том порядке, в котором они определены в коде программы:
metanit.com
С++ - это... Что такое С++?
Проект под названием STLport[2], основанный на SGI STL, осуществляет постоянное обновление STL, IOstream и строковых классов. Некоторые другие проекты также занимаются разработкой частных применений стандартной библиотеки для различных конструкторских задач. Каждый производитель компиляторов Си++ обязательно поставляет какую-либо реализацию этой библиотеки, так как она является очень важной частью стандарта и широко используется.
Объектно-ориентированные особенности языка
Си++ добавляет к Си объектно-ориентированные возможности. Он вводит классы, которые обеспечивают три самых важных свойства ООП: инкапсуляцию, наследование и полиморфизм.
Существует два значения слова класс. В широком смысле класс — это пользовательский тип, объявленный с использованием одного из ключевых слов class, struct или union. В узком смысле класс — это пользовательский тип, объявленный с использованием ключевого слова class.
Инкапсуляция
Основным способом организации информации в Си++ являются классы. В отличие от типа структура (struct) языка Си, которая может состоять только из полей и вложенных типов, класс (class) Си++ может состоять из полей, вложенных типов и функций-членов (member functions). Члены класса бывают публичными (открытыми, public), защищёнными (protected) и собственными (закрытыми, приватными, private). В Си++ тип структура аналогичен типу класс, отличие в том, что по умолчанию члены и базовые классы у структуры публичные, а у класса — собственные.
С открытыми (публичными) членами класса можно делать снаружи класса всё, что угодно. К закрытым (приватным) членам нельзя обращаться извне класса, чтобы не нарушить целостность данных класса. Попытка такого обращения вызовет ошибку компиляции. К таким членам могут обращаться только функции-члены класса (а также так называемые функции-друзья и функции-члены классов-друзей; о понятии друзей в C++ см. ниже). Помимо открытых и закрытых членов класса, могут быть ещё и защищённые — это члены, доступные содержащему их классу, его друзьям, а также производным от него классам. Такая защита членов называется инкапсуляцией.
Используя инкапсуляцию, автор класса может защитить свои данные от некорректного использования. Кроме того, она задумывалась для облегчения совместной разработки классов. Имелось в виду, что при изменении способа хранения данных, если они объявлены как защищённые или собственные, не требуется соответствующих изменений в классах, которые используют изменённый класс. Например, если в старой версии класса данные хранились в виде линейного списка, а в новой версии — в виде дерева, те классы, которые были написаны до изменения формата хранения данных, переписывать не потребуется, если данные были приватными или защищёнными (в последнем случае — если использующие классы не были классами-наследниками), так как ни один из них этих классов не мог бы напрямую обращаться к данным, а только через стандартные функции, которые в новой версии должны уже корректно работать с новым форматом данных. Даже оператор доступа operator [] может быть определён как такая стандартная функция.
Используя инкапсуляцию, структуру Array из предыдущего раздела можно переписать следующим образом:
class Array { public: void Alloc(int new_len); void Free(); inline double Elem(int i); inline void ChangeElem(int i, double x); protected: int len; double* val; }; void Array::Alloc(int new_len) {if (len>0) Free(); len=new_len; val=new double[new_len];} void Array::Free() {delete [] val; len=0;} inline double Array::Elem(int i) {assert(i>=0 && i<len ); return val[i];} inline void Array::ChangeElem(int i, double x) {assert(i>=0 && i<len); val[i]=x;}И далее
Array a; a.Alloc(10); a.ChangeElem(3, 2.78); double b = a.Elem(3); a.Free();Здесь массив a имеет 4 публичных функции-члена и 2 защищённых поля. Описатель inline означает подсказку компилятору, что вместо вызова функции её код следует подставить в точку вызова, чем иногда можно достичь большей эффективности.
Описание функций в теле класса
В теле класса можно указать только заголовок функции, а можно описать всю функцию. Во втором случае она считается встраиваемой (inline), например:
class Array { public: void Alloc(int _len) {if (len==0) Free(); len=_len; val=new double[len];}и так далее.
Конструкторы и деструкторы
Однако в приведённом примере не решена важная проблема: функции Alloc и Free по-прежнему надо вызывать вручную. Другая проблема данного примера — опасность оператора присваивания.
Для решения этих проблем в язык были введены конструкторы и деструкторы. Конструктор вызывается каждый раз, когда создаётся объект данного типа; деструктор — при уничтожении. При преобразованиях типов с участием экземпляров классов тоже вызываются конструкторы и деструкторы.
С конструкторами и деструктором класс выглядит так:
class Array { public: Array() : len(0), val(NULL) {} Array(int _len) : len(_len) {val = new double[_len];} Array(const Array& a); ~Array() { Free(); } inline double Elem(int i); inline void ChangeElem(int i, double x); protected: void Alloc(int _len); void Free(); int len; double* val; }; Array::Array(const Array& a) : len(a.len) { val = new double[len]; for (int i=0; i<len; i++) val[i] = a.val[i]; }Здесь Array::Array — конструктор, а Array::~Array — деструктор. Конструктор копирования (copy constructor) Array::Array(const Array&) вызывается при создании нового объекта, являющегося копией уже существующего объекта. Теперь объект класса Array нельзя испортить: как бы мы его ни создавали, что бы мы ни делали, его значение будет хорошим, потому что конструктор вызывается автоматически. Все опасные операции с указателями спрятаны в закрытые функции.
Array a(5); // вызывается Array::Array(int) Array b; // вызывается Array::Array() Array c(a); // вызывается Array::Array(const Array&) Array d=a; // то же самое b=c; // происходит вызов оператора = // если он не определён (как в данном случае), то вызывается оператор присваивания по умолчанию, который // осуществляет копирование базовых подобъектов и почленное копирование нестатических членов-данных. // как правило конструктор копий и оператор присваивания переопределяются попарноОператор new тоже вызывает конструкторы, а delete — деструкторы.
По умолчанию, каждый класс имеет неявно объявленные конструктор без параметров, копирующий конструктор, копирующий оператор присваивания и деструктор.
Класс может иметь сколько угодно конструкторов (с разными наборами параметров), но только один деструктор (без параметров).
Другие возможности функций-членов
Функции-члены могут быть и операциями:
class Array { ... inline double &operator[] (int n) { return val[n]; }И далее
Array a(10); ... double b = a[5];Функции-члены (и только они) могут иметь описатель const
class Array { ... inline double operator[] (int n) const;Такие функции не имеют права изменять поля класса (кроме полей, определённых как mutable). Если они пытаются это сделать, компилятор должен выдать сообщение об ошибке.
Наследование
Для создания классов с добавленной функциональностью вводят наследование. Класс-наследник имеет поля и функции-члены базового класса, но не имеет права обращаться к собственным (private) полям и функциям базового класса. В этом и заключается разница между собственными и защищёнными членами.
Класс-наследник может добавлять свои поля и функции или переопределять функции базового класса.
По умолчанию, конструктор наследника без параметров вызывает конструктор базового класса, а затем конструкторы нестатических членов-данных, являющихся экземплярами классов. Деструктор работает в обратном порядке. Другие конструкторы приходится определять каждый раз заново. К счастью, это можно сделать вызовом конструктора базового класса.
class ArrayWithAdd : public Array { ArrayWithAdd(int n) : Array(n) {} ArrayWithAdd() : Array() {} ArrayWithAdd(const Array& a) : Array(a) {} void Add(const Array& a); };Наследник — это больше чем базовый класс, поэтому, если наследование открытое, то он может использоваться везде, где используется базовый класс, но не наоборот.
Наследование бывает публичным, защищённым и собственным. При публичном наследовании, публичные и защищённые члены базового класса сохраняют свой статус, а к собственным не могут обращаться даже функции-члены наследника. Защищённое наследование отличается тем, что при нём публичные члены базового класса являются защищёнными членами наследника. При собственном наследовании все члены базового класса становятся собственными членами класса-наследника. Таким образом, пользователь производного класса не может обращаться к членам базового класса, даже если они объявлены как публичные. Класс-наследник делает их собственными с помощью собственного наследования. Как правило, публичное наследование встречается значительно чаще других.
Класс может быть наследником нескольких классов. Это называется множественным наследованием. Такой класс обладает полями и функциями-членами всех его предков. Например, класс FlyingCat (ЛетающийКот) может быть наследником классов Cat (Кот) и FlyingAnimal (ЛетающееЖивотное)
class Cat { ... void Purr(); ... }; class FlyingAnimal { ... void Fly(); ... }; class FlyingCat : public Cat, public FlyingAnimal { ... PurrAndFly() {Purr(); Fly();} ... };Полиморфизм
Полиморфизмом в программировании называется переопределение наследником функций-членов базового класса, например
class Figure { ... void Draw() const; ... }; class Square : public Figure { ... void Draw() const; ... }; class Circle : public Figure { ... void Draw() const; ... };В этом примере, какая из функций будет вызвана — Circle::Draw(), Square::Draw() или Figure::Draw(), определяется во время компиляции. К примеру, если написать
Figure* x = new Circle(0,0,5); x->Draw();то будет вызвана Figure::Draw(), поскольку x — объект класса Figure. Такой полиморфизм называется статическим.
Но в C++ есть и динамический полиморфизм, когда вызываемая функция определяется во время выполнения. Для этого функции-члены должны быть виртуальными.
class Figure { ... virtual void Draw() const; ... }; class Square : public Figure { ... virtual void Draw() const; ... }; class Circle : public Figure { ... virtual void Draw() const; ... }; Figure* figures[10]; figures[0] = new Square(1, 2, 10); figures[1] = new Circle(3, 5, 8); ... for (int i = 0; i < 10; i++) figures[i]->Draw();В этом случае для каждого элемента будет вызвана Square::Draw() или Circle::Draw() в зависимости от вида фигуры.
Чисто виртуальной функцией называется функция-член, которая объявлена со спецификатором = 0:
class Figure { ... virtual void Draw() const = 0; );Чисто виртуальная функция может быть оставлена без определения, кроме случая, когда требуется произвести её вызов. Абстрактным классом называется такой, у которого есть хотя бы одна чисто виртуальная функция-член. Объекты таких классов создавать запрещено. Абстрактные классы часто используются как интерфейсы.
Друзья
Функции-друзья — это функции, не являющиеся функциями-членами и тем не менее имеющие доступ к защищённым и собственным полям и функциям-членам класса. Они должны быть описаны в теле класса как friend. Например:
class Matrix { ... friend Matrix Multiply(Matrix m1, Matrix m2); ... }; Matrix Multiply(Matrix m1, Matrix m2) { ... }Здесь функция Multiply может обращаться к любым полям и функциям-членам класса Matrix.
Существуют также классы-друзья. Если класс A — друг класса B, то все его функции-члены могут обращаться к любым полям и функциям членам класса B. Например:
class Matrix { ... friend class Vector; ... };Однако в С++ не действует правило «друг моего друга — мой друг».
По стандарту C++03 вложенный класс не имеет прав доступа к закрытым членам объемлющего класса и не может быть объявлен его другом (последнее следует из определения термина друг как нечлена класса). Тем не менее, многие широко распространённые компиляторы нарушают оба эти правила (по всей видимости, ввиду совокупной странности этих правил).
Будущее развитие
Текущий стандарт языка был принят в 2003 году. Следующая версия стандарта носит неофициальное название C++0x.
Си++ продолжает развиваться, чтобы отвечать современным требованиям. Одна из групп, занимающихся языком Си++ в его современном виде и направляющих комитету по стандартизации Си++ советы по его улучшению — это Boost. Например, одно из направлений деятельности этой группы — совершенствование возможностей языка путём добавления в него особенностей метапрограммирования.
Стандарт Си++ не описывает способы именования объектов, некоторые детали обработки исключений и другие возможности, связанные с деталями реализации, что делает несовместимым объектный код, созданный различными компиляторами. Однако для этого третьими лицами создано множество стандартов для конкретных архитектур и операционных систем.
Тем не менее (по состоянию на время написания этой статьи) среди компиляторов Си++ всё ещё продолжается битва за полную реализацию стандарта Си++, особенно в области шаблонов — части языка, совсем недавно полностью разработанной комитетом стандартизации.
Ключевое слово export
Одной из точек преткновения в этом вопросе является ключевое слово export, используемое также и для разделения объявления и определения шаблонов.
Первым компилятором, поддерживающим export в шаблонах, стал Comeau C++ в начале 2003 года (спустя пять лет после выхода стандарта). В 2004 году бета-версия компилятора Borland C++ Builder X также начала его поддержку.
Оба этих компилятора основаны на внешнем интерфейсе EDG. Другие компиляторы, такие как Microsoft Visual C++ или GCC (GCC 3.4.4), вообще этого не поддерживают. Герб Саттер (англ.), секретарь комитета по стандартизации Си++, рекомендовал убрать export из будущих версий стандарта по причине серьёзных сложностей в полноценной реализации, однако впоследствии окончательным решением было решено его оставить.
Из списка других проблем, связанных с шаблонами, можно привести вопросы конструкций частичной специализации шаблонов, которые плохо поддерживались в течение многих лет после выхода стандарта Си++.
Си++ не включает в себя Си
Несмотря на то что большая часть кода Си будет справедлива и для Си++, Си++ не является надмножеством Си и не включает его в себя. Существует и такой верный для Си код, который неверен для Си++. Это отличает его от Объектного Си, ещё одного усовершенствования Си для ООП, как раз являющегося надмножеством Си.
Например, следующий фрагмент кода корректен с точки зрения Си, но некорректен с точки зрения Си++:
typedef struct mystr { int a; int b; } mystr;Дело в том, что в Си идентификаторы структур (теги структур), то есть идентификаторы, используемые при описании структуры в качестве имени структуры, являются сущностями отдельного вида, имеющими обособленное пространство имён, тогда как в Си++ идентификатор структуры представляет собой попросту её тип. Таким образом, в языке Си вышеприведённый фрагмент вводит структуру mystr и новый тип mystr, тогда как в Си++ этот же фрагмент будет воспринят как попытка дважды описать тип с именем mystr.
Другим источником несовместимости являются добавленные ключевые слова. Так, описание переменной
является вполне корректным для Си, но заведомо ошибочным для Си++, поскольку слово try является в Си++ ключевым.
Существуют и другие различия. Например, Си++ не разрешает вызывать функцию main() внутри программы, в то время как в Си это действие правомерно. Кроме того, Си++ более строг в некоторых вопросах; например, он не допускает неявное приведение типов между несвязанными типами указателей и не разрешает использовать функции, которые ещё не объявлены.
Более того, код, верный для обоих языков, может давать разные результаты в зависимости от того, компилятором какого языка он оттранслирован. Например, на большинстве платформ следующая программа печатает «С», если компилируется компилятором Си, и «С++» — если компилятором Си++. Так происходит из-за того, что символьные константы в Си (например 'a') имеют тип int, а в Си++ — тип char, а размеры этих типов обычно различаются.
#include <stdio.h> int main() { printf("%s\n", (sizeof('a') == sizeof(char)) ? "C++" : "C"); return 0; }Примеры программ на Си++
Пример № 1
Это пример программы, которая не делает ничего. Она начинает выполняться и немедленно завершается. Она состоит из основного потока: функции main(), которая обозначает точку начала выполнения программы на Си++.
Стандарт Си++ требует, чтобы функция main() возвращала тип int. Программа, которая имеет другой тип возвращаемого значения функции main(), не соответствует стандарту Си++.
Стандарт не говорит о том, что на самом деле означает возвращаемое значение функции main(). Традиционно оно интерпретируется как код возврата программы. Стандарт гарантирует, что возвращение 0 из функции main() показывает, что программа была завершена успешно.
Завершение программы на Си++ с ошибкой традиционно обозначается путём возврата ненулевого значения.
Пример № 2
Эта программа также ничего не делает, но более лаконична.
В Си++, если выполнение программы доходит до конца функции main(), то это эквивалентно return 0;. Это неверно для любой другой функции кроме main().
Пример № 3
Это пример программы Hello World, которая выводит это знаменитое сообщение, используя стандартную библиотеку, и завершается.
#include <iostream> // это необходимо для std::cout и std::endl int main() { std::cout << "Hello, world!" << std::endl; }Пример № 4
Современный Си++ позволяет решать простым способом и более сложные задачи. Этот пример демонстрирует кроме всего прочего использование контейнеров стандартной библиотеки шаблонов (STL).
#include <iostream> // для использования std::cout #include <vector> // для std::vector<> #include <map> // для std::map<> и std::pair<> #include <algorithm> // для std::for_each() #include <string> // для std::string using namespace std; // используем пространство имён "std" void display_item_count(pair< string const, vector<string> > const& person) { // person - это пара двух объектов: person.first - это его имя, // person.second - это список его предметов (вектор строк) cout << person.first << " is carrying " << person.second.size() << " items" << endl; } int main() { // объявляем карту со строковыми ключами и данными в виде векторов строк map< string, vector<string> > items; // Добавим в эту карту пару человек и дадим им несколько предметов items["Anya"].push_back("scarf"); items["Dimitri"].push_back("tickets"); items["Anya"].push_back("puppy"); // Переберём все объекты в контейнере for_each(items.begin(), items.end(), display_item_count); }В этом примере для простоты используется директива использования пространства имён, в настоящей же программе обычно рекомендуется использовать объявления, которые аккуратнее директив:
#include <vector> int main() { using std::vector; vector<int> my_vector; }Здесь директива помещена в область функции, что уменьшает шансы столкновений имён (это и стало причиной введения в язык пространств имён). Использование объявлений, сливающих разные пространства имён в одно, разрушает саму концепцию пространства имён.
Сравнение C++ с языками Java и C#
Целью создания C++ было расширение возможностей Си, наиболее распространённого языка системного программирования. Ориентированный на ту же самую область применения, C++ унаследовал множество не самых лучших, с теоретической точки зрения, особенностей Си. Перечисленные выше принципы, которых придерживался автор языка, предопределили многие недостатки C++.
В области прикладного программирования альтернативой C++ стал его язык-потомок, Майкрософт предложила язык C#, представляющий собой ещё одну переработку C++ в том же направлении, что и Java. В дальнейшем появился язык функционального программирования. Ещё позже появилась попытка объединения эффективности C++ с безопасностью и скоростью разработки C# — был предложен язык D, который пока не получил широкого признания.
Java и C++ можно рассматривать как два языка-потомка Си, разработанных из различных соображений и пошедших, вследствие этого, по разным путям. В этой связи представляет интерес сравнение данных языков (всё, сказанное ниже про Java, можно с равным успехом отнести к языкам C# и Nemerle, поскольку в рассматриваемых деталях эти языки отличаются лишь внешне).
Синтаксис C++ сохраняет совместимость с C, насколько это возможно. Java сохраняет внешнее подобие C и C++, но, в действительности, сильно отличается от них — из языка удалено большое число синтаксических средств, признанных необязательными. В результате Java гораздо проще C++, что облегчает как изучение языка, так и создание трансляторов для него. Исполнение программы Java-код компилируются в промежуточный код, который в дальнейшем интерпретируется или компилируется, тогда как C++ изначально ориентирован на компиляцию в машинный код заданной платформы (хотя, теоретически, ничто не мешает создавать для C++ трансляторы в промежуточный код). Это уже определяет разницу в сферах применения языков: Java вряд ли может быть использована при написании таких специфических программ, как драйвера устройств или низкоуровневые системные утилиты. Механизм исполнения Java делает программы, даже откомпилированные (в байт-код) полностью переносимыми. Стандартное окружение и среда исполнения позволяют выполнять программы на Java на любой аппаратной платформе и в любой ОС, без каких-либо изменений, усилия по портированию программ минимальны (при соблюдении рекомендаций по созданию переносимых программ — и вовсе нулевые). Ценой переносимости становится потеря эффективности — работа среды исполнения приводит к дополнительным накладным расходам. Управление памятью C++ следует классической технике управления памятью, когда программист, выделяя динамически память под объекты, обязан позаботиться о своевременном её освобождении. Java работает в среде со сборкой мусора, которая автоматически отслеживает прекращение использования объектов и освобождает занимаемую ими память. Первый вариант предпочтительнее в системном программировании, где требуется полный контроль программиста над используемыми программой ресурсами, второй удобнее в прикладном программировании, поскольку в значительной степени освобождает программиста от необходимости отслеживать момент прекращения использования ранее выделенной памяти. Сборщик мусора Java требует системных ресурсов, что также снижает эффективность выполнения программ. Стандартизация окружения В Java есть чётко определённые стандарты на ввод-вывод, графику, геометрию, диалог, доступ к базам данных и прочим типовым приложениям. C++ в этом отношении гораздо более свободен. Стандарты на графику, доступ к базам данных и т. д. являются недостатком, если программист хочет определить свой собственный стандарт. Указатели C++ сохраняет возможность работы с низкоуровневыми указателями. В Java указателей нет. Использование указателей часто является причиной труднообнаруживаемых ошибок, но необходимо для низкоуровневого программирования. В принципе, C++ обладает набором средств (конструкторы и деструкторы, стандартные шаблоны, ссылки), позволяющих почти полностью исключить выделение и освобождение памяти вручную и опасные операции с указателями. Однако такое исключение требует определённой культуры программирования, в то время как в языке Java оно реализуется автоматически. Парадигма программирования Язык Java является чисто объектно-ориентированным, тогда как C++ сохраняет возможности чисто процедурного программирования (свободные функции и переменные). Динамическая информация о типах В C++ отсутствует полноценная информации о типах во время исполнения RTTI. Эту возможность можно было бы реализовать в C++, имея полную информацию о типах во время компиляции CTTI. Препроцессор C++ сохранил препроцессор Си, в том числе возможность введения пользовательского синтаксиса с помощью #define. Этот механизм небезопасен, он может привести к тому, что модули в крупных пакетах программ становятся сильно связаны друг с другом, что резко понижает надёжность пакетов и возможность организации разделённых модулей. С++ предоставляет достаточно средств (константы, шаблоны, встроенные функции) для того, чтобы практически полностью исключить использование #define. Java просто исключила препроцессор полностью, избавившись разом от всех проблем с его использованием, хотя и потеряв при этом некоторые возможности.Отличия языков приводят к ожесточённым спорам между сторонниками двух языков о том, какой язык лучше. Споры эти во многом беспредметны, поскольку сторонники Java считают различия говорящими в пользу Java, а сторонники C++ полагают обратное. Некоторая аргументация устаревает со временем, например, упрёки в неэффективности Java из-за наличия среды исполнения, бывшие справедливыми в первой половине 1990-х годов, в результате лавинообразного роста производительности компьютеров и появления более эффективной техники исполнения (
Далеко не все программисты являются сторонниками одного из языков. По мнению большинства программистов, Java и C++ не являются конкурентами, потому что обладают различными областями применимости. Другие считают, что выбор языка для многих задач является вопросом личного вкуса.
Достоинства и недостатки языка
Прежде всего, необходимо подчеркнуть, что оценивать достоинства и, в особенности, недостатки С++ необходимо в контексте тех принципов, на которых строился язык, и требований, которые к нему изначально предъявлялись.
Достоинства
C++ — чрезвычайно мощный язык, содержащий средства создания эффективных программ практически любого назначения, от низкоуровневых утилит и драйверов до сложных программных комплексов самого различного назначения. В частности:
- Высокая совместимость с языком С, позволяющая использовать весь существующий С-код (код С может быть с минимальными переделками скомпилирован компилятором С++; библиотеки, написанные на С, обычно могут быть вызваны из С++ непосредственно без каких-либо дополнительных затрат, в том числе и на уровне функций обратного вызова, позволяя библиотекам, написанным на С, вызывать код, написанный на С++).
- Поддерживаются различные стили и технологии программирования, включая традиционное директивное программирование, ООП, обобщенное программирование, метапрограммирование (шаблоны, макросы).
- Имеется возможность работы на низком уровне с памятью, адресами, портами.
- Возможность создания обобщённых контейнеров и алгоритмов для разных типов данных, их специализация и вычисления на этапе компиляции, используя шаблоны.
- Кроссплатформенность. Доступны компиляторы для большого количества платформ, на языке C++ разрабатывают программы для самых различных платформ и систем.
- Эффективность. Язык спроектирован так, чтобы дать программисту максимальный контроль над всеми аспектами структуры и порядка исполнения программы. Ни одна из языковых возможностей, приводящая к дополнительным накладным расходам, не является обязательной для использования — при необходимости язык позволяет обеспечить максимальную эффективность программы.
Недостатки
Отчасти недостатки C++ унаследованы от языка-предка — Си, — и вызваны изначально заданным требованием возможно большей совместимости с Си. Это такие недостатки, как:
- Синтаксис, провоцирующий ошибки:
- Операция присваивания обозначается как = , а операция сравнения как ==. Их легко спутать, при этом операция присваивания возвращает значение, поэтому присваивание на месте выражения является синтаксически корректным, а в конструкциях цикла и ветвления появление числа на месте логического значения также допустимо, так что ошибочная конструкция оказывается синтаксически правильной. Типичный пример подобной ошибки: if (x=0) { операторы } Здесь в условном операторе по ошибке написано присваивание вместо сравнения. В результате, вместо того, чтобы сравнить текущее значение x с нулём, программа присвоит x нулевое значение, а потом интерпретирует его как значение условия в операторе if. Так как нуль соответствует логическому значению «ложь» (false), блок операторов в условной конструкции не выполнится никогда. Ошибки такого рода трудно выявлять, но во многих современных компиляторах предлагается диагностика некоторых подобных конструкций.
- Операции присваивания (=), инкрементации (++), декрементации (--) и другие возвращают значение. В сочетании с обилием операций это позволяет, хотя и не обязывает, создавать трудночитаемые выражения. Наличие этих операций в Си было вызвано желанием получить инструмент ручной оптимизации кода, но в настоящее время оптимизирующие компиляторы обычно генерируют оптимальный код и на традиционных выражениях. С другой стороны, один из основных принципов языков C и C++ — позволять программисту писать в любом стиле, а не навязывать «хороший» стиль.
- Макросы (#define) являются мощным, но опасным средством. Они сохранены в C++ несмотря на то, что необходимость в них, благодаря шаблонам и встроенным функциям, не так уж велика. В унаследованных стандартных С-библиотеках много потенциально опасных макросов.
- Некоторые преобразования типов неинтуитивны. В частности, операция над беззнаковым и знаковым числами выдаёт беззнаковый результат.
- Необходимость записывать break в каждой ветви оператора switch и возможность последовательного выполнения нескольких ветвей при его отсутствии провоцирует ошибки из-за пропуска break. Эта же особенность позволяет делать сомнительные «трюки», базирующиеся на избирательном неприменении break и затрудняющие понимание кода.
- Препроцессор, унаследованный от С, очень примитивен. Это приводит с одной стороны к тому, что с его помощью нельзя (или тяжело) осуществлять некоторые задачи метапрограммирования, а с другой, вследствие своей примитивности, он часто приводит к ошибкам и требует много действий по обходу потенциальных проблем. Некоторые языки программирования (например, Nemerle) имеют намного более мощные и более безопасные системы метапрограммирования (также называемые макросами, но мало напоминающие макросы С/С++).
- Плохая поддержка модульности (по сути, в классическом Си модульность на уровне языка отсутствует, её обеспечение переложено на компоновщик). Подключение интерфейса внешнего модуля через препроцессорную вставку заголовочного файла (#include) серьёзно замедляет компиляцию при подключении большого количества модулей (потому что результирующий файл, который обрабатывается компилятором, оказывается очень велик). Эта схема без изменений скопирована в C++. Для устранения этого недостатка, многие компиляторы реализуют механизм прекомпиляции заголовочных файлов Precompiled Headers.
К собственным недостаткам C++ можно отнести:
- Сложность и избыточность, из-за которых C++ трудно изучать, а построение компилятора сопряжено с большим количеством проблем. В частности:
- В языке практически полностью сохранён набор конструкций Си, к которому добавлены новые средства. Во многих случаях новые средства и механизмы позволяют делать то же самое, что и старые, но в языке сохраняются оба варианта.
- Поддержка множественного наследования реализации в ООП-подсистеме языка вызывает целый ряд логических проблем, а также создаёт дополнительные трудности в реализации компилятора.
- Шаблоны в своём исходном виде приводят к порождению кода очень большого объёма, а введённая позже в язык возможность частичной спецификации шаблонов трудно реализуема и не поддерживается многими существующими компиляторами.
- Недостаток информации о типах данных во время компиляции (CTTI).
- Метапрограммирование на основе шаблонов C++ сложно и при этом ограничено в возможностях. Оно состоит в реализации средствами шаблонов C++ интерпретатора примитивного функционального языка программирования выполняющегося во время компиляции. Сама по себе данная возможность весьма привлекательна, но такой код весьма трудно воспринимать и отлаживать. Языки Lisp/Nemerle и некоторые другие имеют более мощные и одновременно более простые для восприятия подсистемы метапрограммирования. Кроме того, в языке D реализована сравнимая по мощности, но значительно более простая в применении подсистема шаблонного метапрограммирования.
- Хотя декларируется, что С++ мультипарадигменный язык, реально в языке отсутствует поддержка функционального программирования. Отчасти, данный пробел устраняется различными библиотеками (Boost) использующими средства метапрограммирования для расширения языка функциональными конструкциями (например, поддержкой лямбд/анонимных методов), но качество подобных решений значительно уступает качеству встроенных в функциональные языки решений. Такие возможности функциональных языков, как сопоставление с образцом, вообще крайне сложно эмулировать средствами метапрограммирования.
- Некоторые считают недостатком языка C++ отсутствие встроенной системы сборки мусора. С другой стороны, в C++ имеется достаточно средств, позволяющих почти исключить использование опасных указателей, нет принципиальных проблем и в реализации и использовании сборки мусора (на уровне библиотек, а не языка). Отсутствие встроенной сборки мусора позволяет пользователю самому выбрать стратегию управления ресурсами.
Примечания
См. также
Ссылки
Статьи и книги, библиотеки материалов по C++ Форумы- codeby.net C, С++ и С Builder. Белорусский форум по C++
- www.rsdn.ru/forum/?group=cpp — форум по C++ на
- Bloodshed Dev-C++ (сайт) — бесплатная и свободная среда разработки в C++ под Windows.
- (сайт) — бесплатная и свободная кроссплатформенная среда разработки.
- Blitz++ — библиотека научных программ на C++, с упором на линейную алгебру
- The Matrix Template Library — линейная алгебра на C++
- Boost C++ Libraries — свободные кроссплатформенные библиотеки на C++
- GNU Scientific Library — свободная математическая библиотека для C/C++, распространяемая на условиях лицензии GNU General Public License.
- The C++ Standards Committee
- VivaCore — свободная библиотека для создания систем статического анализа Си/Си++ кода [1].
- сайт) — бесплатная открытая библиотека для создания своего пользовательского интерфейса.
- сайт) — ещё одна библиотека создания кроссплатформенных приложений, бесплатная для некоммерческого использования.
Литература
- Страуструп Б. Язык программирования C++. Специальное издание = The C++ programming language. Special edition. — М.: Бином-Пресс, 2007. — 1104 с. — ISBN 5-7989-0223-4
- Герберт Шилдт. Полный справочник по C++ = C++: The Complete Reference. — 4-е изд. — М.: Вильямс, 2006. — 800 с. — ISBN 0-07-222680-3
- Джесс Либерти, Дэвид Хорват. Освой самостоятельно C++ за 24 часа = Sams Teach Yourself C++ in 24 Hours, Complete Starter Kit. — 4-е изд. — М.: Вильямс, 2007. — 448 с. — ISBN 0-672-32681-7
- Стефенс Д. Р. C++. Сборник рецептов. — КУДИЦ-ПРЕСС, 2007. — 624 с. — ISBN 5-91136-030-6
dic.academic.ru
Что такое +C в SAMP?
+С это ускорение стрельбы из Deagle, его делать так: Пельиваешься, стреляешь, нажимаешь С и делаешь так много раз
техника стрельбы с дигла без отдачи. У самого не получается
Как Делать +C 0_o
лкм пкм с и всё изи
+c это баг сампа позволяющий убирать отдачу от стрельбы и тем самым стрелять быстрее посмотри школу стрельбы на ютубе и узнаешь как делать
жмёшь прицел стреляешь быстро убираешь прицел и жмёшь c
+С это ускорение стрельбы из Deagle, его делать так: Пельиваешься, стреляешь, нажимаешь С и делаешь так много раз
Многие спрашивают что такой +С сейчас я обьясню это: Слив анимации и багоюз!
touch.otvet.mail.ru
Что такое USB Type-C?
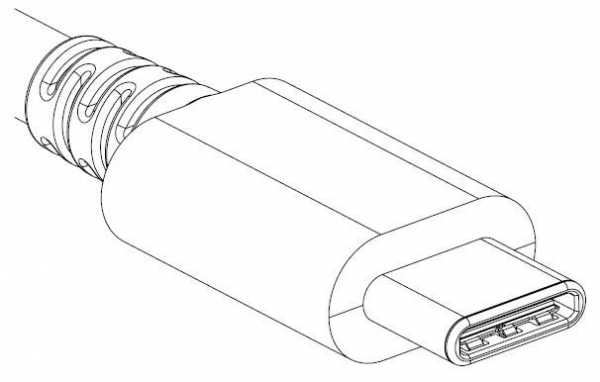
Ранее в этом месяце новый «гуру» компании Apple Тим Кук анонсировал ряд новых продуктов, наиболее интересным из которых оказалась усовершенствованная версия MacBook Air. В ходе своего выступления Кук уделял слишком много внимания возможностям и функциям, которые больше не являются столь уникальными, как Apple хочет заставить нас поверить. Поэтому одна из самых ключевых и интригующих инноваций Air, технология с потенциалом серьезно изменить мир мобильных устройств в течение следующих нескольких лет, осталась почти незамеченной. Речь идет о новом разъеме USB Type-C и исключительно широком спектре возможностей, которые он предлагает.
Что такое USB Type-C?
Как подсказывает название стандарта – это эволюционная доработка известного формата универсальной последовательной шины (USB), которая в настоящее время является одним из наиболее распространенных интерфейсов в сфере компьютерной периферии и мобильных технологий. Type-C не просто обеспечивает обратную совместимость с предыдущими версиями USB, но и объединяет их новым, уникальным способом. Так один кабель (интерфейс) может передавать данные, электроэнергию и даже видео.

 По своему размеру разъем типа C меньше, чем хронологически наиболее старый (и массовый) стандарт Type-A, но немного больше формата microUSB (Type Micro-B). В отличие от своих предшественников, однако, новый стандарт является более универсальным – разъем кабеля Type-C можно подключать к порту любой стороной и с обеих сторон кабеля располагаются одинаковые штекеры. В то же время это ограничивает обратную совместимость с уже существующими форматами Type-A и Type-B. Иначе говоря, вы не сможете подключить кабель Type-A или B в порт Type-C и наоборот.
По своему размеру разъем типа C меньше, чем хронологически наиболее старый (и массовый) стандарт Type-A, но немного больше формата microUSB (Type Micro-B). В отличие от своих предшественников, однако, новый стандарт является более универсальным – разъем кабеля Type-C можно подключать к порту любой стороной и с обеих сторон кабеля располагаются одинаковые штекеры. В то же время это ограничивает обратную совместимость с уже существующими форматами Type-A и Type-B. Иначе говоря, вы не сможете подключить кабель Type-A или B в порт Type-C и наоборот. Зато порт Type-C можно без проблем настроить так, чтобы он мог выполнять множество разных функций. Так, например, кабель USB Type-C может спокойно передавать сигнал HDMI или DisplayPort, хотя на данный момент эта возможность все еще чисто теоретическая.
Type-C? Разве это не USB 3.1?
Определенно нет! USB 3.1 является последней версией стандарта передачи данных, который (по крайней мере, в теории) должен удвоить пиковую скорость передачи данных с 5 Gbps (USB 3.0) до 10 Gbps. Кроме того, 3.1 полностью обратно совместим с предыдущими версиями стандарта: 3.0 и 2.0.
В этом ключе, модуль Type-C может предлагать как возможности для передачи данных через USB 3.1, так и через некоторые из более старых стандартов. Например, адаптер USB Type-C Digital АV Multiport, который Apple будет предлагать в качестве дополнительного аксессуара для нового MacBook, по спецификации поддерживает «USB 3.1 Gen 1» с теоретической максимальной пропускной способностью 5 Gbps, т.е. практически идентично стандарту USB 3.0. А одно из первых устройств с поддержкой Type-C, которое в отличие от MacBook 2015 уже доступно на рынке, планшет Nokia N1, использует еще более старый USB 2.0 для передачи данных и зарядки.
Type-C = USB Power Delivery?
Снова нет. Power Delivery является частью последней спецификации стандарта USB и представляет собой возможность передачи до 100 Вт мощности к любому подключенному устройству, хотя он также может использоваться и для передачи данных. Для сравнения, самый популярный сейчас стандарт USB 2.0, который используется почти во всех смартфонах и планшетах, обеспечивает передачу до 2.5 Вт мощности. Это одна из причин, почему вы не можете заряжать большинство современных ноутбуков через USB – они требуют напряжение между 20 и 65 Вт. Однако с новым разъемом Power Delivery вы сможете не только спокойно заряжать ваш будущий ноутбук через USB, но и одновременно с этим смотреть 4K видео, передаваемое на внешний монитор, который подключен тем же самым кабелем.
Так какая связь между Type-C и USB Power Delivery? Здесь мы снова говорим о теоретической возможности поддержки. Другими словами – разъем Type-C может предложить возможности USB Power Delivery, если производитель соответствующего модуля предусмотрит это. В противном случае, если у вас есть кабель Type-C, это не означает, что он поддерживает и Power Delivery.
Type-C сегодня? Или скорее завтра?
Несмотря на свои многочисленные, красивые обещания, на данный момент новый MacBook это все еще просто куча блестящих характеристик. В отличие от Apple, однако, ряд компаний уже предлагают на рынке устройства с поддержкой Type-C. Первой стала Nokia с вышеупомянутым планшетом N1.

SanDisk недавно показала свой первый флэш-диск на основе нового стандарта. Тем не менее, чтобы обеспечить обратную совместимость со старыми форматами USB, это 32-гигабайтное устройство располагает и дополнительным разъемом Type-A – практика, которая, вероятно, будет часто встречаться во время перехода на новый стандарт.
В рамках январской выставки CES 2015 был продемонстрирован прототип док-станции для ноутбуков, которая предлагает разъем Type-C для зарядки и вывода видео на внешний 4К-дисплей. А компания LaCie буквально на днях объявила, что намерена предложить серию Type-C-внешних жестких дисков с емкостью 500 ГБ, 1 и 2 ТБ.
windowstips.ru
Организация W3C. Стандарты HTML W3C
 Всем привет. Сегодняшняя тема статьи продолжает самую первую тему об основных тегах HTML, к которой был оставлен комментарий, что один из тегов не соответствует текущим стандартам W3C. Так вот, что это за стандарт, кем он писан и собственно, что такое, это W3C? Но, прежде отойду от темы и за одно расскажу одну новость. Теперь на блоге появилась новая рубрика школа WPGet. Основная цель — это уроки по WEB-разработке, а именно уроки по HTML, CSS, PHP, JS и другим технологиям. Не скрою, что в этом я еще сам новичок, поэтому эта школа сделана больше чтобы обучиться самому этим технологиям. И параллельно обучать вас, дорогие читатели. Кстати этот прием одновременно немного расширит тематику блога, но она так же будет посвящена разработке сайтов на основе WordPress. И да, самая главная цель, это научится решать реальные задачи, а не только задачки из учебников, вот тогда я и буду уверен в своих знаниях.
Всем привет. Сегодняшняя тема статьи продолжает самую первую тему об основных тегах HTML, к которой был оставлен комментарий, что один из тегов не соответствует текущим стандартам W3C. Так вот, что это за стандарт, кем он писан и собственно, что такое, это W3C? Но, прежде отойду от темы и за одно расскажу одну новость. Теперь на блоге появилась новая рубрика школа WPGet. Основная цель — это уроки по WEB-разработке, а именно уроки по HTML, CSS, PHP, JS и другим технологиям. Не скрою, что в этом я еще сам новичок, поэтому эта школа сделана больше чтобы обучиться самому этим технологиям. И параллельно обучать вас, дорогие читатели. Кстати этот прием одновременно немного расширит тематику блога, но она так же будет посвящена разработке сайтов на основе WordPress. И да, самая главная цель, это научится решать реальные задачи, а не только задачки из учебников, вот тогда я и буду уверен в своих знаниях.
Что такое W3C стандарты
W3C (World Wide Web Consortium/ Консорциум Всемирной паутины) – это организация, которая занимается внедрением новых технологий в WEB и их стандартизацией. (Напомнили мне немного Intel, которые помешаны на стандартизации всего и вся). Так нам говорит википедия. Давайте разберемся теперь подробней их деятельность. Эта организация, возглавляемая одним из сооснователей всемирной паутины Тимом Бернес-Ли, который является изобретателем URL, HTML, HTTP и других технологий.
Основная цель создания WEB стандартов — возможность взаимодействия различных программных продуктов. Соответственно это разработка программных продуктов в соответствии со стандартами и в итоге качественный IT продукт. На картинке ниже список стандартов, которые утвердил W3C:

Что такое стандарт конкретно? Иными словами стандарт это соответствие текущим правилам разработки на определенном языке. Например, вы разрабатываете ресурс на HTML, который имеет стандарт, включающий в себя определенные теги и исключающий старые менее эффективные теги прошлых его стандартов/версий. Если ваш ресурс использует теги в соответствии с текущими стандартами, то он считается ресурсом с валидным кодом, но если вы использовали старые теги, которые уже не входят в состав нового стандарта, то ваш продукт имеет не валидный код. Но это не значит, что теги не будут работать. Кстати незакрытые теги также считаются отклонением от стандарта.
Соблюдение стандартов W3C сугубо личное дело каждого разработчика, но, разумеется, при создании действительно качественного и публичного продукта, стоит придерживаться всех стандартов. Стандарты проверяются специальными программами/сервисами, которые называются валидаторы. Вот для примера валидатор HTML и валидатор CSS. При помощи низ, вы можете проверить, насколько вы соответствуете или не соответствуете текущим стандартам. Кстати сами стандарты можно посмотреть на официальном сайте W3C тут.
Таким образом, один из тегов в первом уроке, а именно тег center не входит в текущий стандарт HTML, что валидатор сочтет за несоответствие стандарту. Именно поэтому баннеры под шапкой моего блога были убраны. На данный момент ищу альтернативу прошлому решению. На этом пока все. Основные две наши цели в ближайшее время это уроки по HTML и CSS. В следующем уроке создадим свой первый HTML документ с использованием CSS и проверим его на валидность.
wpget.ru